Classification Part 2
Fundamentals of Machine Learning for NHS using R
Guess Who?
- Out of the below what yes/no question would you ask first?
- Is your character male?
- Is your character wearing glasses?
- Do they have a moustache?
- Does your character have blonde hair?
Guess Who?
Asking if the character is male is the best first question, as it eliminates the most options, there are multiple hair colours, and not all the characters have hair!
However there is only the option of male or female in this case, and each character can be assigned to one or the other.
Guess Who?
- Suppose I asked the following questions with these results to obtain this value.
- Is the character male? No
- Is the character wearing glasses? Yes
- Does your character have brown hair? Yes
- Is your Character wearing a necklace? No

Guess who?
Here is the entire decision tree for Guess Who? 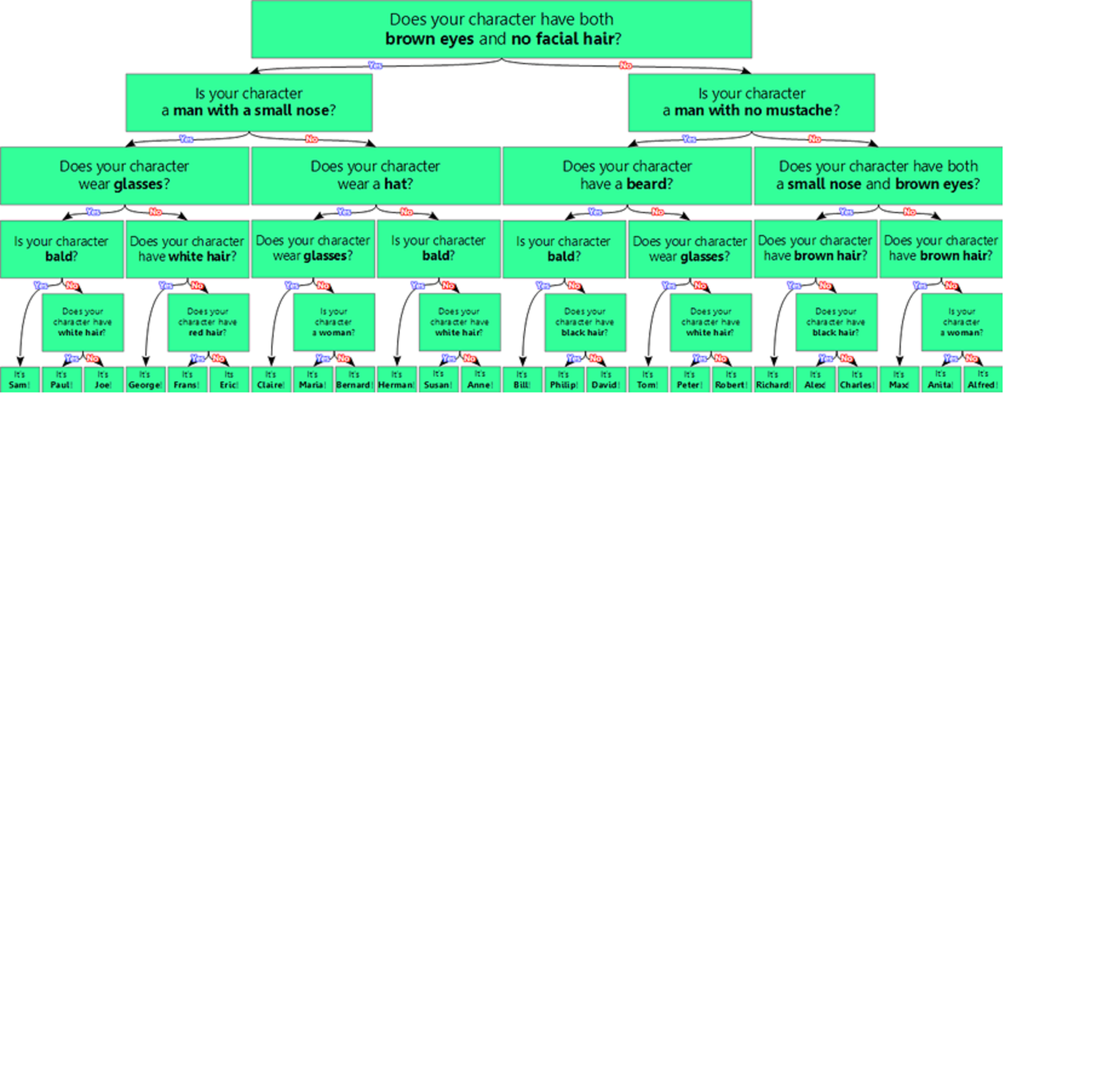
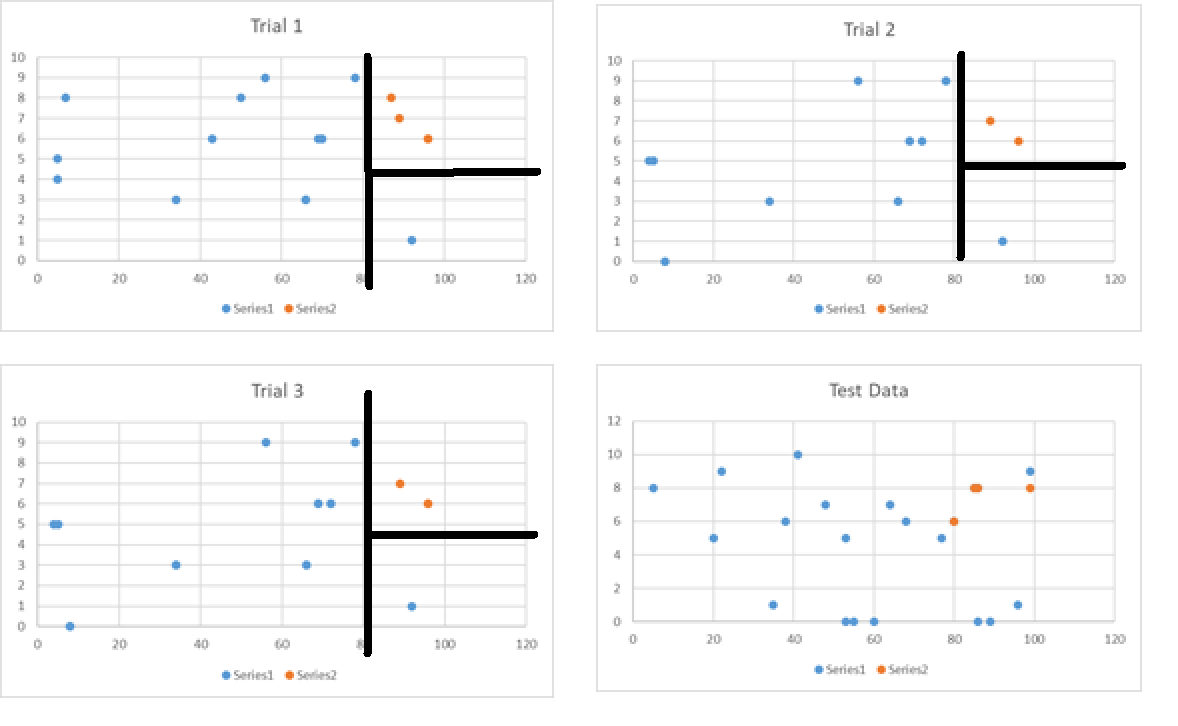
Information Gain - Example
The plot shows the number of days spent doing a hobby, how many days they work, and if they are happy or sad. What yes or no questions would you ask to determine if someone is happy or sad?

Information Gain - Example
Question 1: Do you spend less than 3 Days doing a hobby?
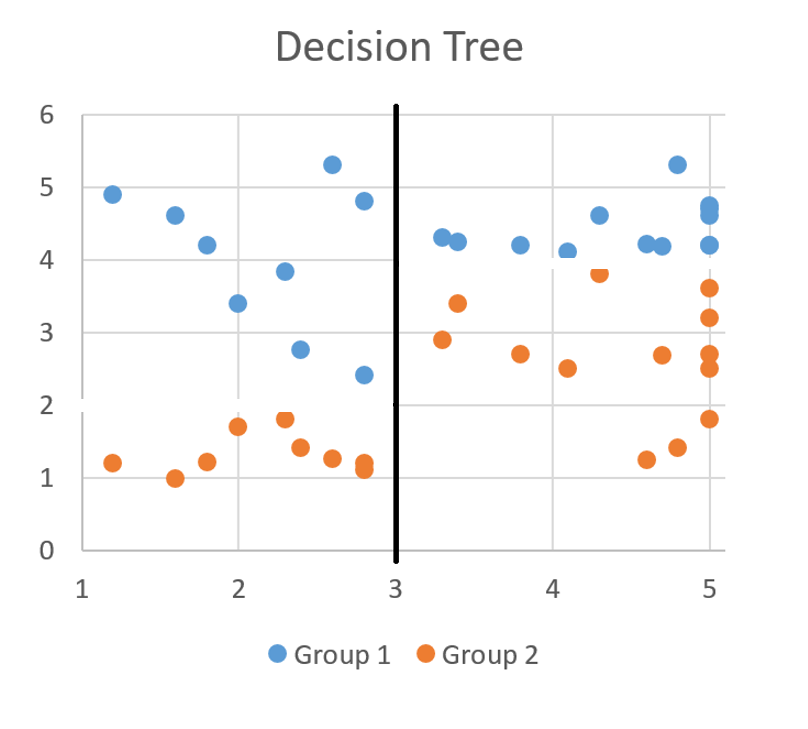
Information Gain - Example
- Question 2 : What would you ask if I said yes?
- Question 3: What would you ask if I said no?
Information Gain - Example
- What would you ask if I said yes?
- Question 2 : Is the number of days spent in work less than 2?
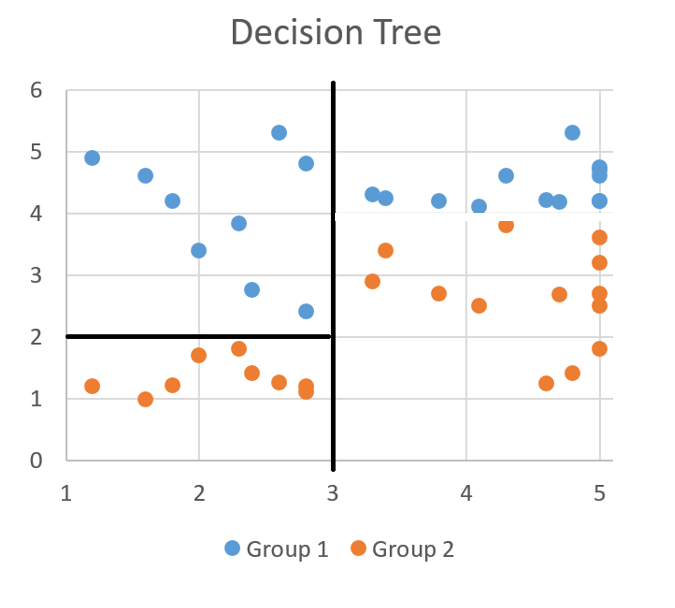
Information Gain - Example
- What would you ask if I said no?
- Question 3 : Is the number of days spent in work less than 4?
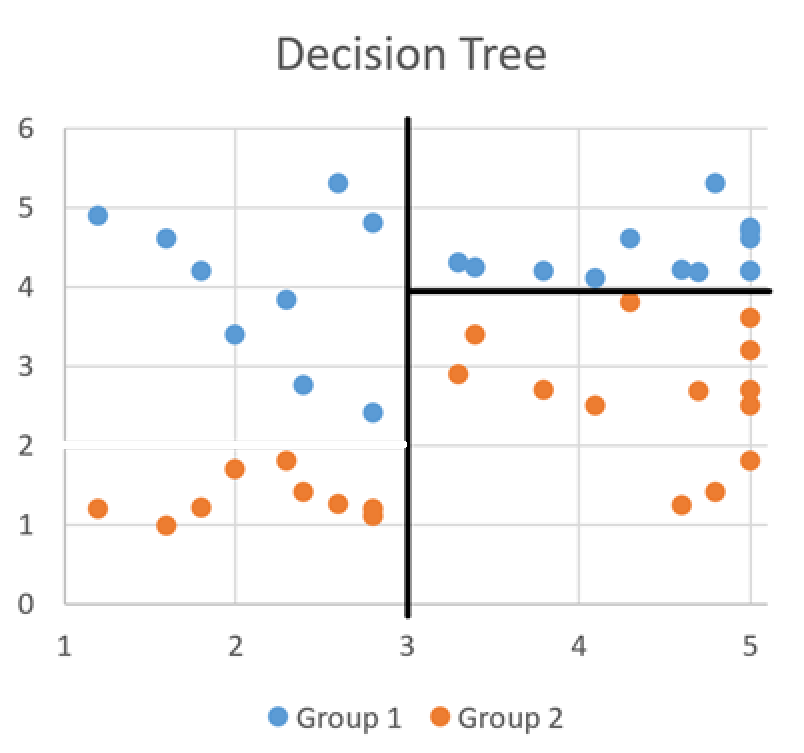
Information Gain - Example
Do you think we could use the model to classify if they are happy or sad? Y - is the number of days spent in work. X - is the number days spent doing a hobby.
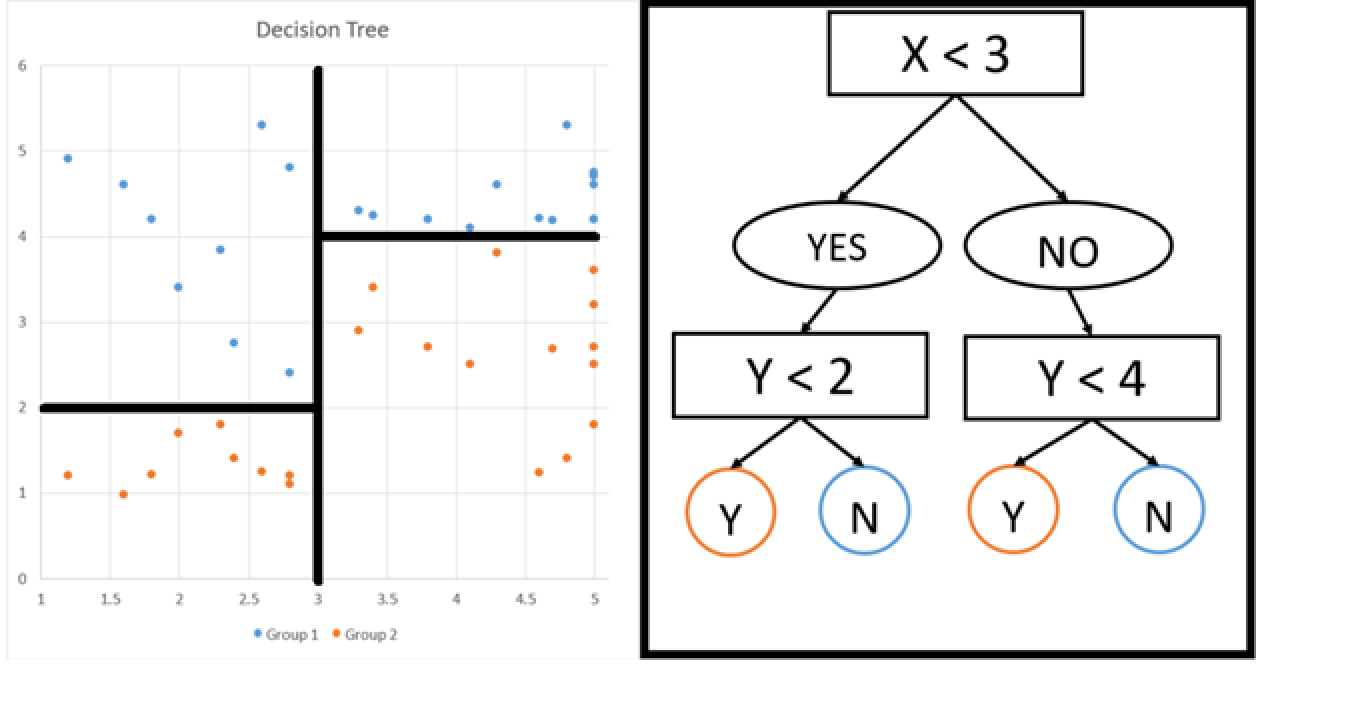
Information Gain - Example
For some additional data, collected in the same way, can our model predict if these people were happy or sad.
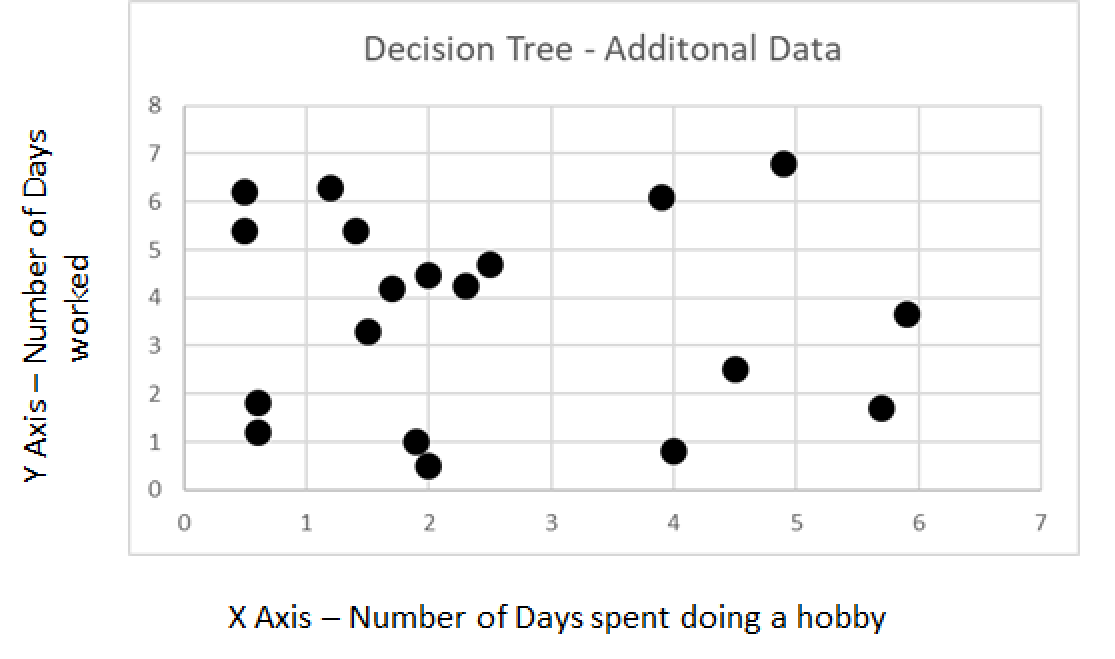
Information Gain - Example
Our model would suggest that these people were either happy or sad in the following way.
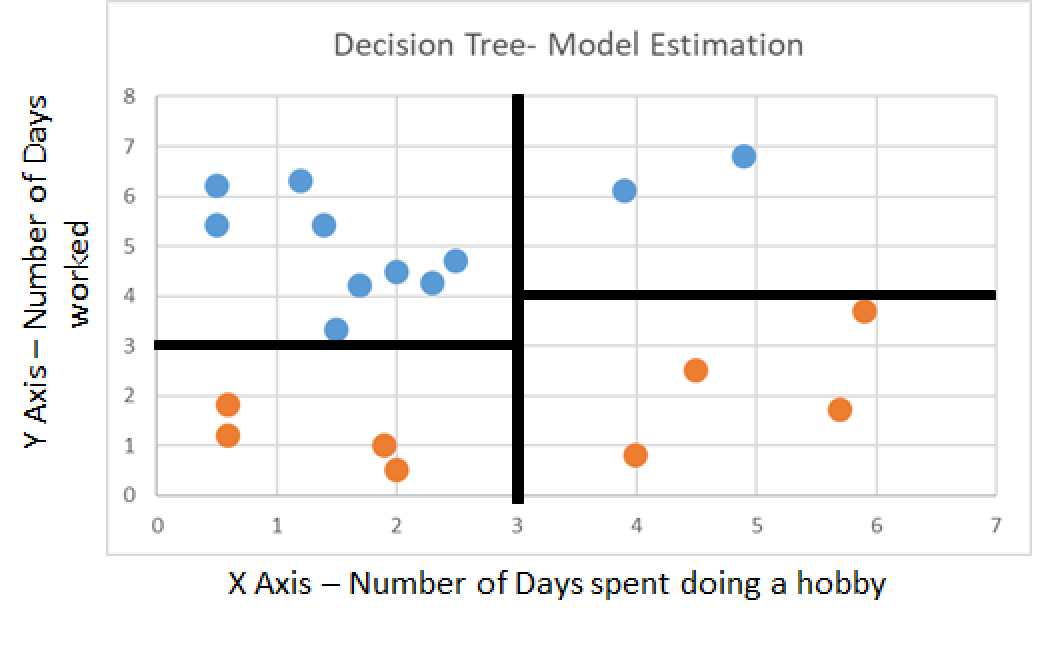
Information Gain - Example
Estimate groupings based on model 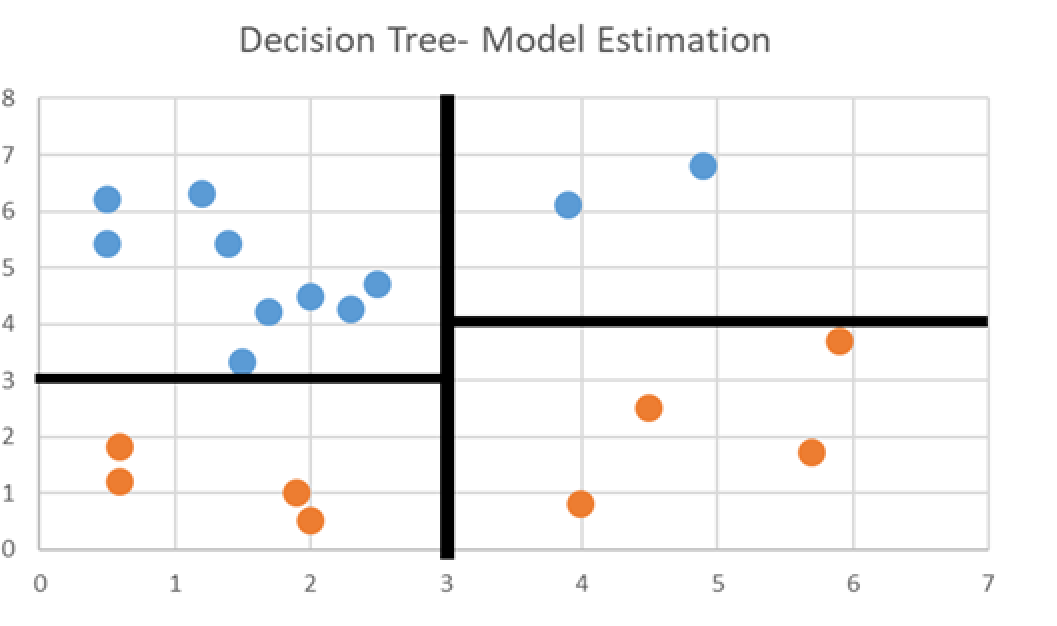
Actual groupings from collected data 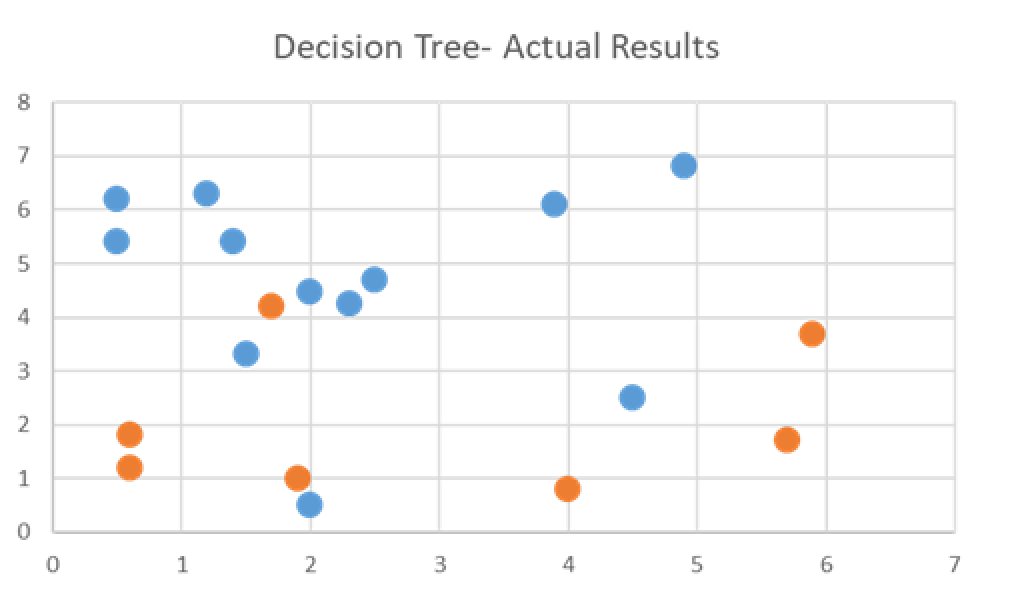
Entropy
In our example, “Do you have a beard”, is no longer a question that gives any information, that being it brings us no closer to our answer.
Entropy
- Entropy in a sense measures the randomness of an event.
- If I picked a character, and you randomly guessed who I was. This would have an entropy of 1 (complete random).
- If you wanted to guess my character, but knew he had short blonde hair and was wearing a suit. The Entropy would be 0, as you would be absolutely certain of the outcome (Alex).
Entropy
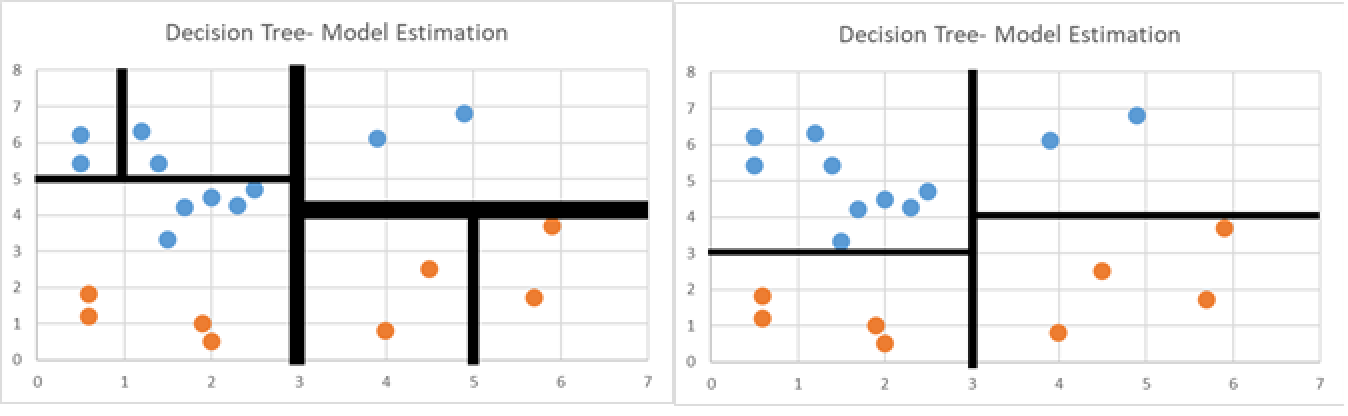
- Decision Trees that aim to have lower Entropy, have to ask less questions to solve the problem.
- While both below have the same accuracy, one has a much higher Entropy, and delves on overfitting.
![]()
Bagging & Boosting
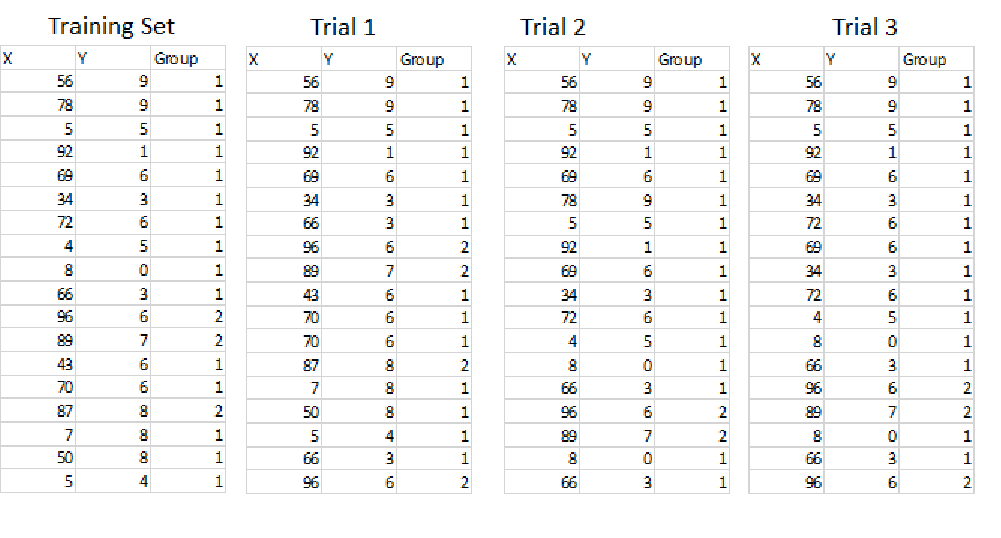
- Suppose I have a training set. With T = 3, so three trials.
- Notice that some examples are repeated.
![]()
Bagging & Boosting