Feature Engineering
Fundamentals of Machine Learning for NHS using R
Today’s Plan
- Feature Engineering
- Feature engineering techniques including but not limited to: transformations, feature extraction, reduction and selection.
Data transformation
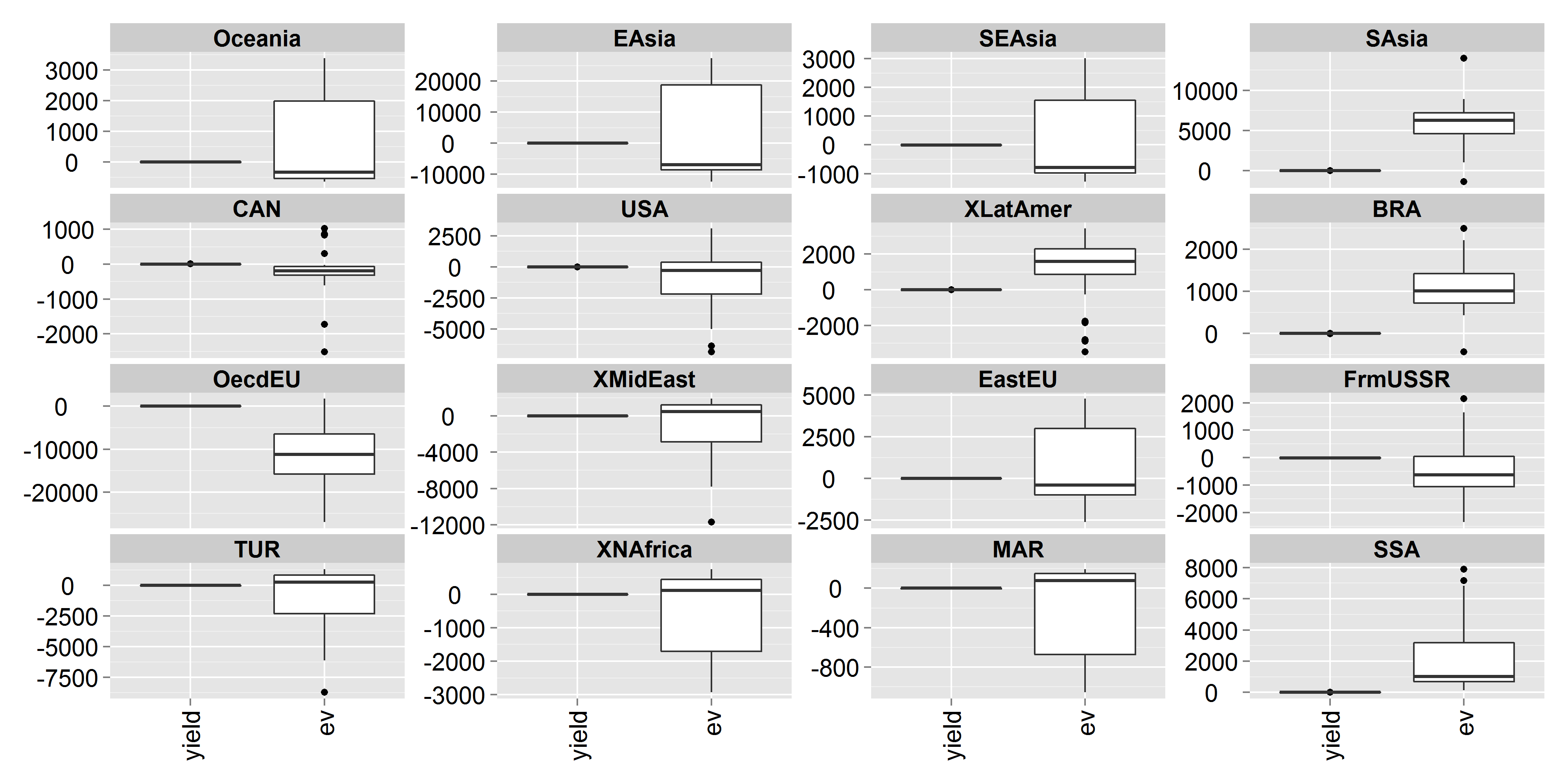
- Once data cleaning is complete, we need to consolidate the quality data into alternate forms by changing the value, structure, or format of data.
- Generally machine learning models are difficult to understand when the input numerical variables have different scales.
Data transformation
Data transformation
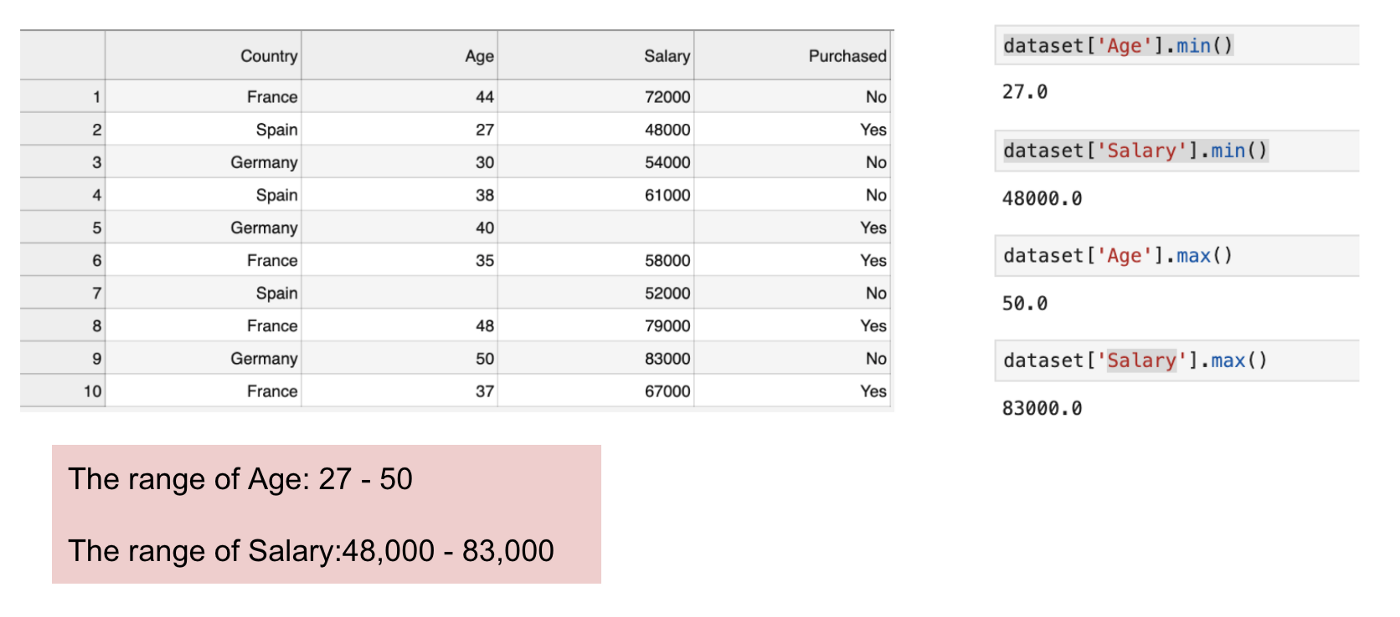
- Min-max Normalisation
- Values are shifted and rescaled so they end up ranging from 0 to 1
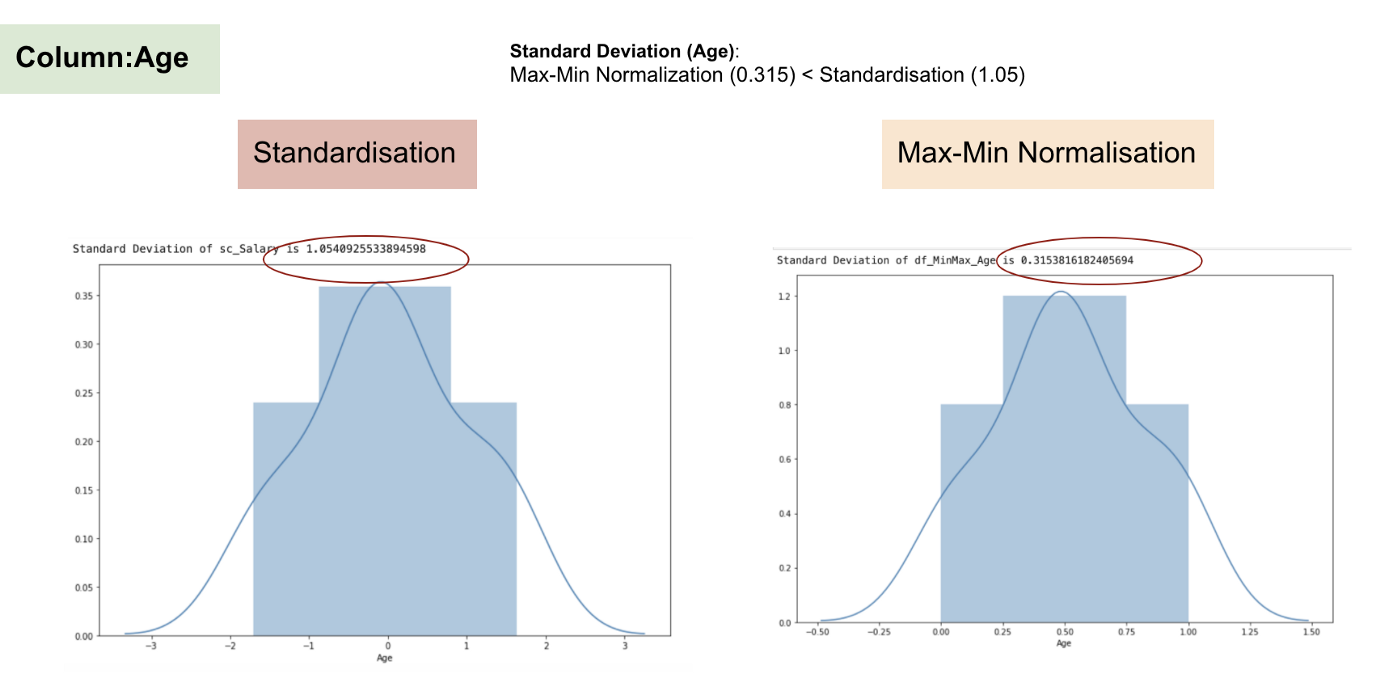
- Standardisation
- Subtracts the mean value from each index and divide by standard deviation, resulting into a new distribution with unit variance
Data transformation

Data transformation
Data transformation
Feature Engineering
Categorical variables
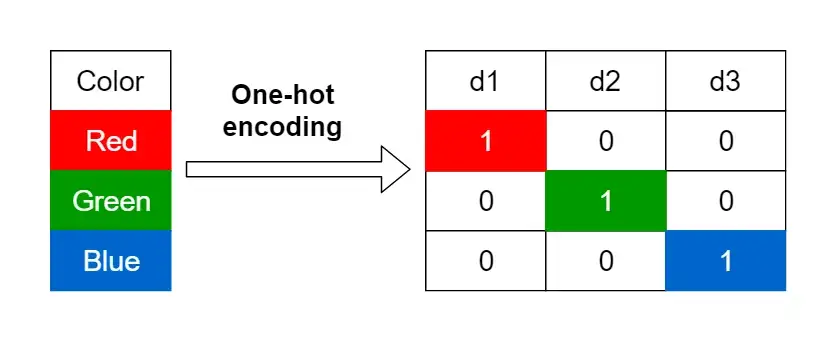
- Also known as creating dummy variables.
- Categorical features are replaced by one or more new features which can have numerical values.
- Any number of categories can be represented by introducing one new feature per category.
Feature Engineering
Categorical variables
Feature Engineering
Categorical variables
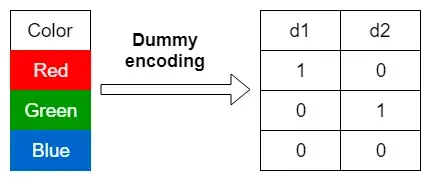
When to one-hot encode and dummy encode
- Both types of encoding can be used to encode ordinal and nominal categorical variables.
- However, if you strictly want to keep the natural order of an ordinal categorical variable, you can use label encoding instead.
Label encoding
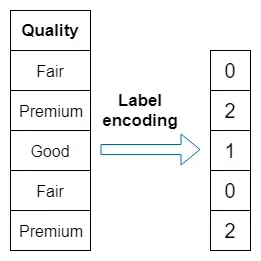
Advantages & disadvantages
- One advantage of label encoding is that it does not expand the feature space at all as we just replace category names with numbers.
- The major disadvantage of label encoding is that machine learning algorithms may consider there may be relationships between the encoded categories.
- For example, an algorithm may interpret Premium (2) as two times better than Good (1).
Feature Engineering
Continuous variables
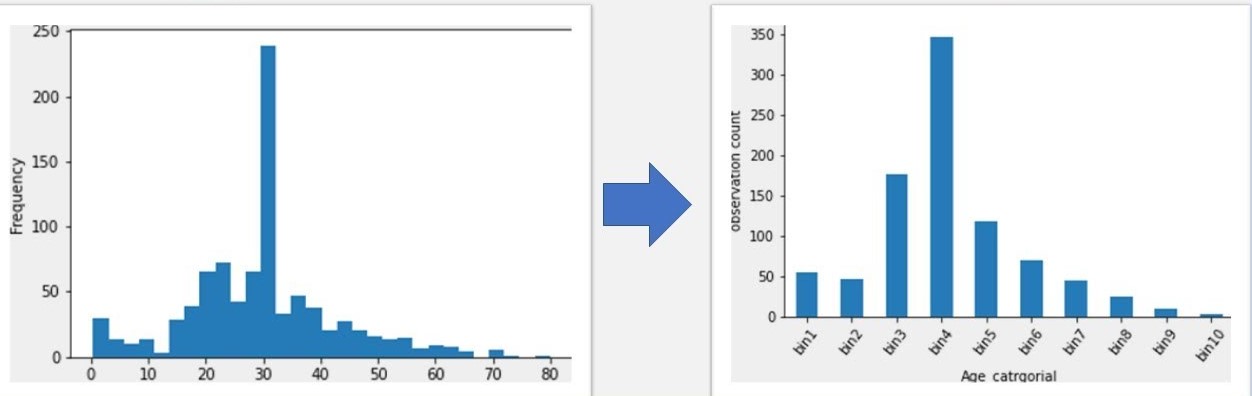
- Binning takes a numeric predictor and pre-categorises or “bins” it into two or more groups.
- Binning can be used to create new features or can be used to simply categorise features as they are.
- There could be certain drawbacks to binning continuous data when being used as features for ML models. There can be a loss of precision in the predictions when the predictors are categorised.
Binning
Feature selection
- Removing predictors - fewer predictors mean less computational time and complexity.
- Collinearity - the situation where a pair of predictor variables have a substantial correlation with each other.
- Remove if: two predictors are highly correlated, discard one?
- We shouldn’t just blindly follow the correlation rule. We can use the highly correlated features to create new features.
Feature selection
- These methods reduce the data by generating a smaller set of predictors.
- They capture the majority of the information in the original variables.
- Fewer variables can be used that provide reasonable fidelity to the original data.
- For most data reduction techniques, the new predictors are functions of the original predictors.
Thank you!
Questions?