


install.packages("package_name")Introduction to Tidyverse
Fundamentals of Data Science for NHS using R
What is R?
R is a language and environment for statistical computing and graphics.
R provides a wide variety of statistical and graphical techniques, and is highly extensible.
![]()
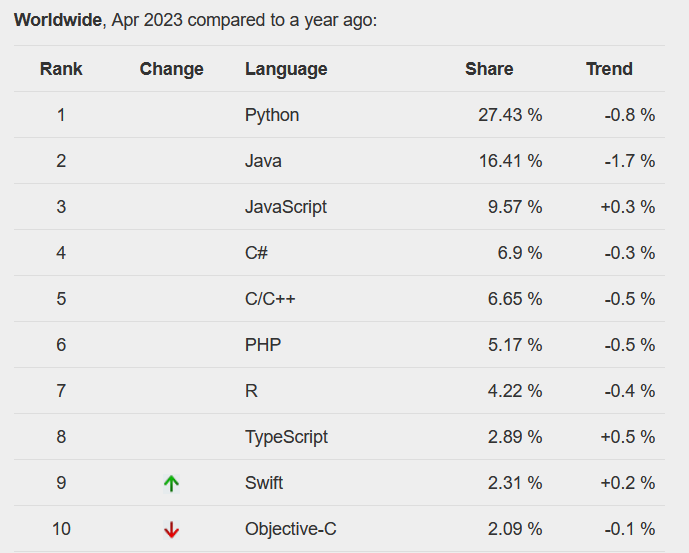
R Popularity
R is popular even if it’s just for statistics and data analysis!
R is ranked 16th in the TIOBE index and 7th in the PYPL index
NHS-R Community
Promoting the Use of R in the UK Health & Care System.
![]()
What is RStudio?
RStudio is an integrated development environment (IDE) for R developed by Posit PBC.
RStudio PBC changed its name to Posit PBC last summer.
![]()

Posit Cloud
Data Science Workflow
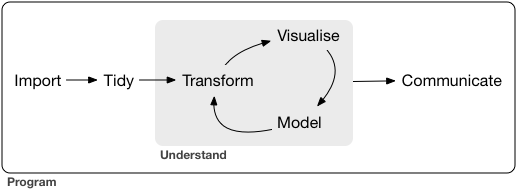
Tidy Data
Tidy data is data where:
- Every column is variable.
- Every row is an observation.
- Every cell is a single value.

What is the Tidyverse?
Tideverse is a collection of R packages designed for data science.

ggplot2
Data visualisation

dplyr
Data manipulation

tidyr
Data tidying

readr
Data import (CSV and TSV files)

purrr
Functional programming

tibble
tibble data structure

stringr
Strings manipulation

forcats
Categorical variables

lubridate
Dates manipulations

hms
Time-of-day values manipulation

Import other formats
reprex
Ask for help in way that everybody can understand.

magrittr
Provides the %>% operator which is essential to write cleaner code.
From R 4.1.0 (May 2021) the pipe operator has been implemented in the base-R language and its syntax is |>.
See this link for differences.

R for Data Science
This is where you should start!
R for Data Science work-in-progress 2nd edition by Hadley Wickham, Mine Çetinkaya-Rundel, Garrett Grolemund.

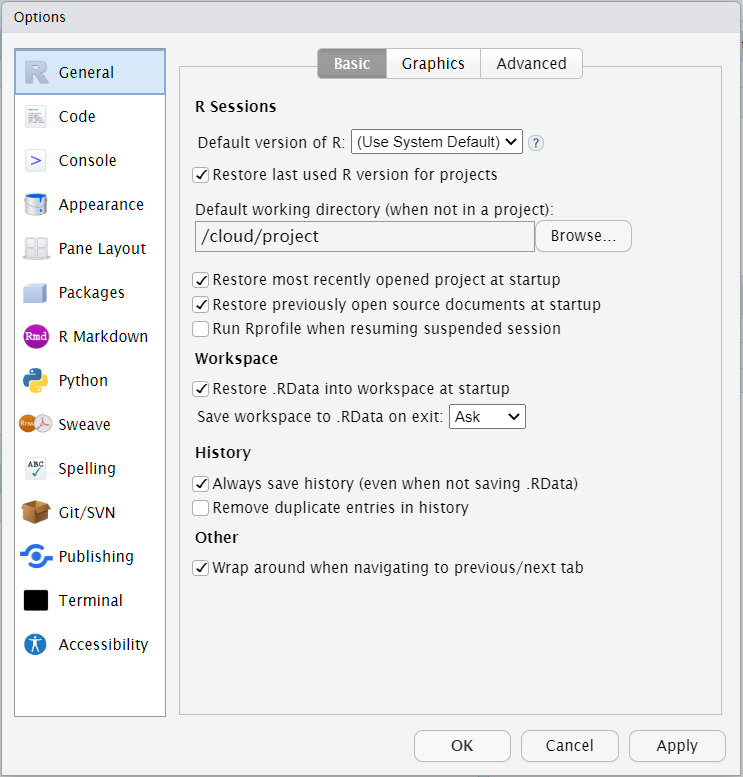
Custumize RStudio
The available options for the RStudio IDE are accessible from the Tools > Options menu.
A full reference of the available options can be found here.
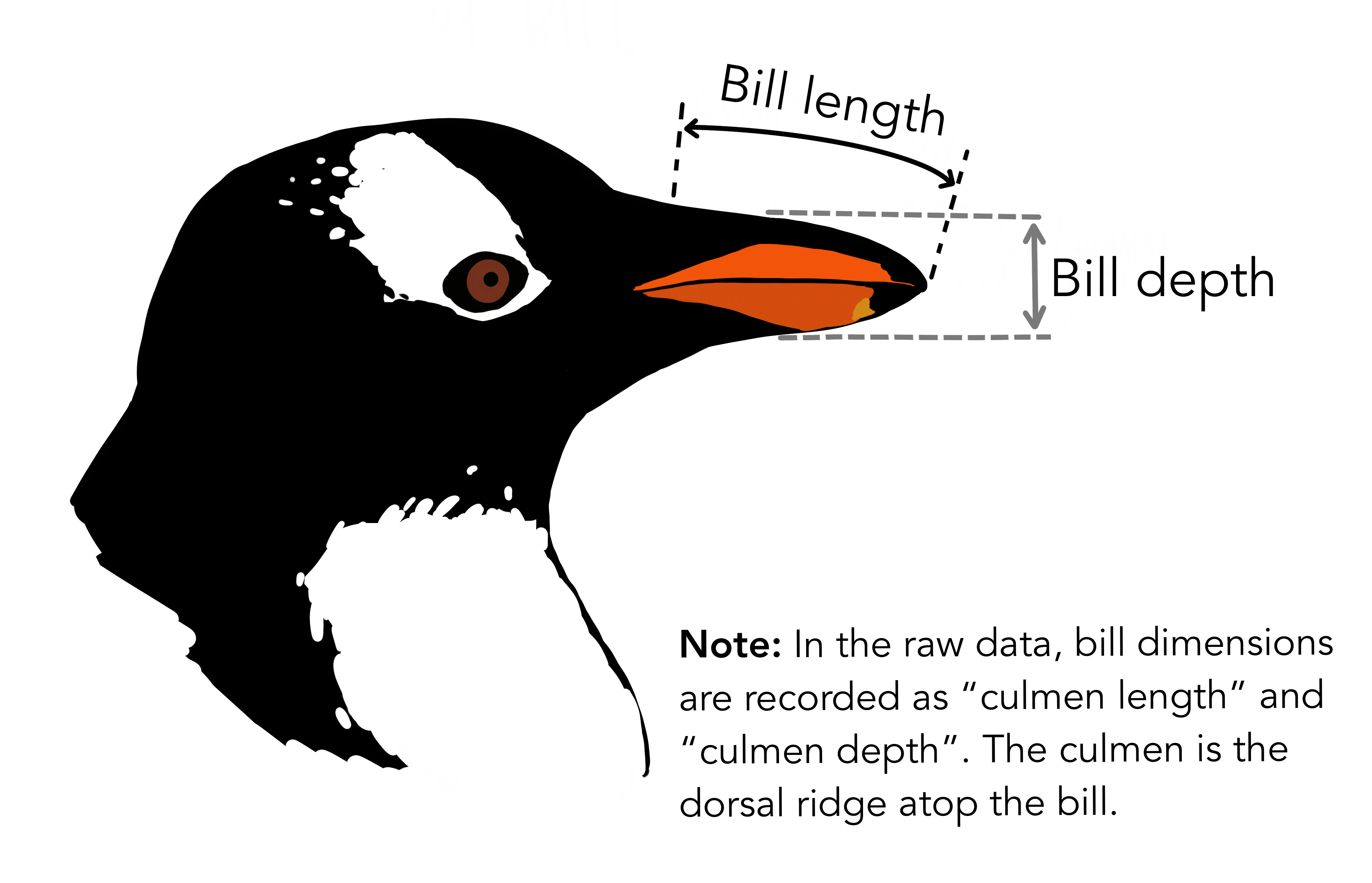
Palmer Penguins
The goal of palmerpenguins is to provide a great dataset for data exploration and visualization.

Palmer Penguins Variables

dplyr cheat sheet
